Validation
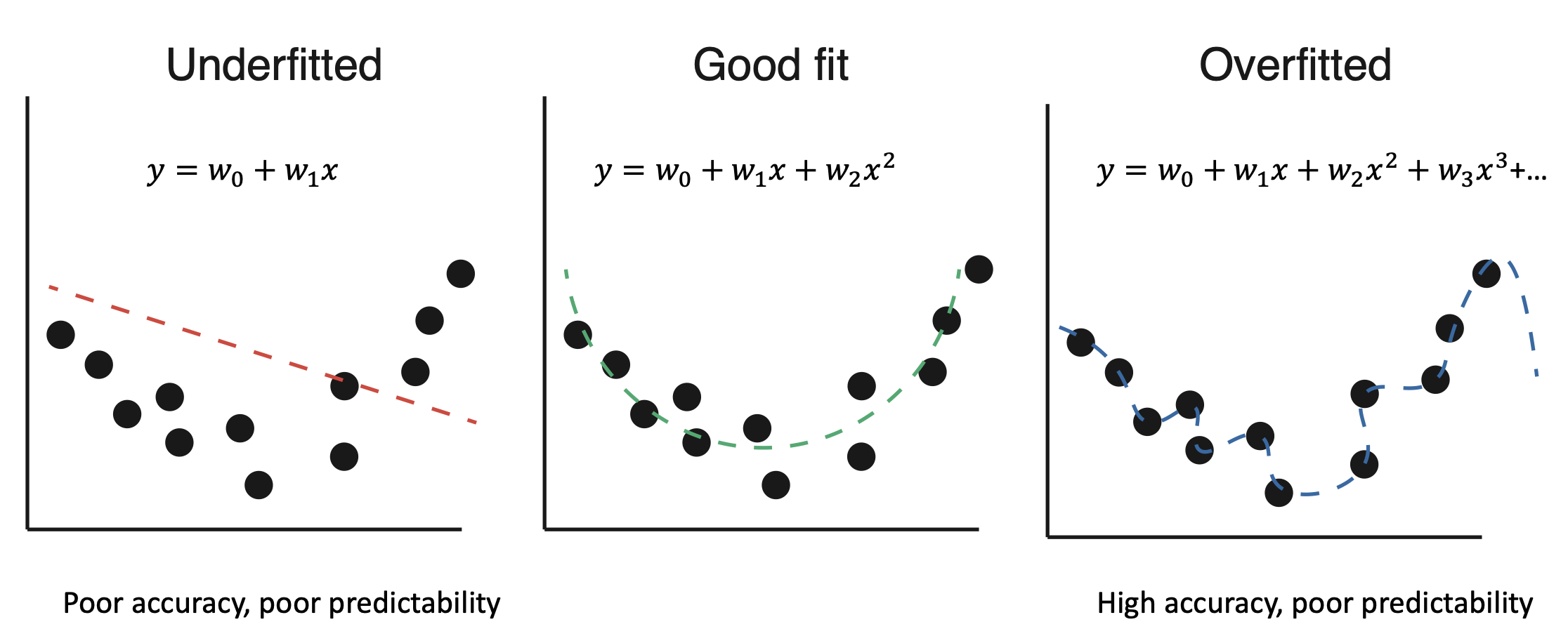
Overfitting and underfitting in machine learning models. Overfitting occurs when a model learns the training data too well, capturing noise and outliers, while underfitting occurs when a model is too simple to capture the underlying patterns in the data.
Validation is the process of evaluating a model’s performance on a separate dataset that was not used during training. This helps to ensure that the model generalizes well to unseen data and is not overfitting to the training set. The goal of validation is to find the right balance between bias and variance. Regularization techniques can be used to control overfitting and underfitting.
Data Splitting¶
Most machine learning workflows involve splitting the dataset into three parts:
Training Set: Used to train the model.
Validation Set: Used to tune hyperparameters and evaluate the model’s performance during training.
Test Set: Used to evaluate the final model’s performance after training and validation.
The training set should be large enough to allow the model to learn effectively, while the validation and test sets should be representative of the data the model will encounter in real-world applications.
Cross-Validation¶
Cross-validation is a technique used to assess how the results of a statistical analysis will generalize to an independent dataset. It is primarily used in settings where the goal is prediction and one wants to estimate how accurately a predictive model will perform in practice.
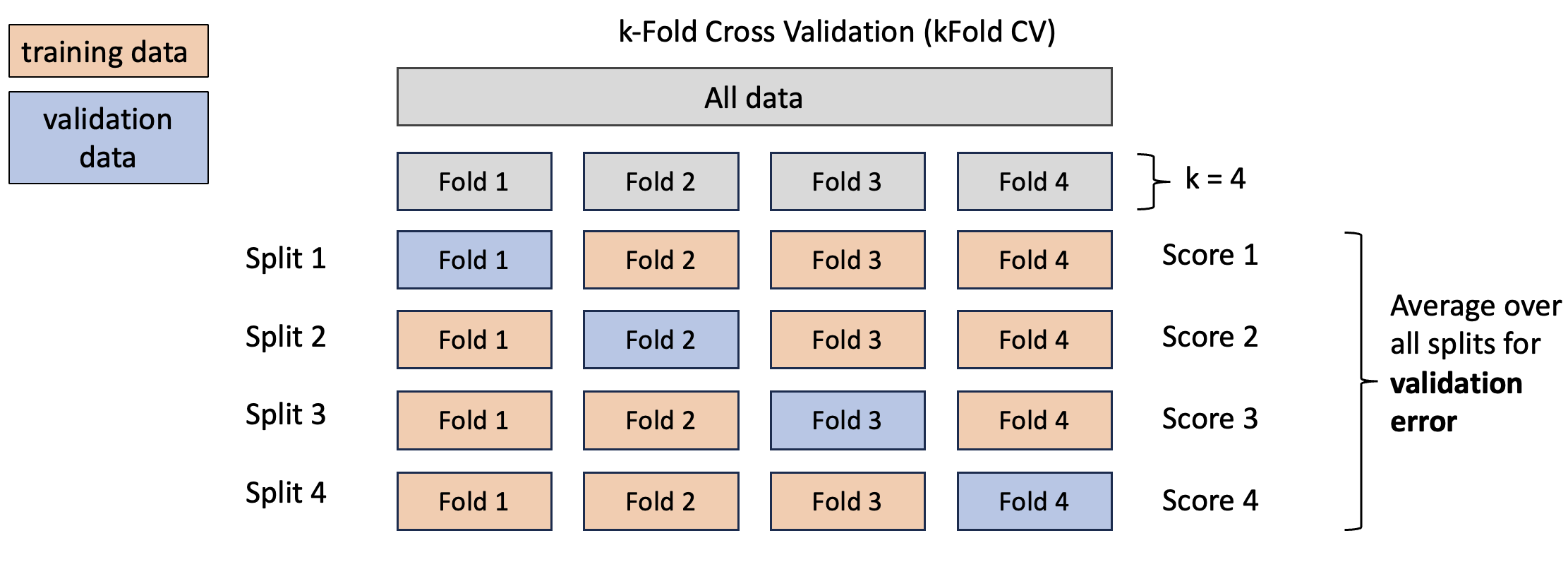
K-fold cross-validation. The dataset is divided into k subsets (or “folds”). The model is trained on k-1 folds and validated on the remaining fold. This process is repeated k times, with each fold being used as the validation set once. The final performance metric is typically the average of the performance across all k folds.
The most common form of cross-validation is k-fold cross-validation, where the dataset is divided into k subsets (or “folds”). The model is trained on k-1 folds and validated on the remaining fold. This process is repeated k times, with each fold being used as the validation set once. The final performance metric is typically the average of the performance across all k folds.
This approach helps to mitigate the risk of overfitting and provides a more reliable estimate of the model’s performance on unseen data.